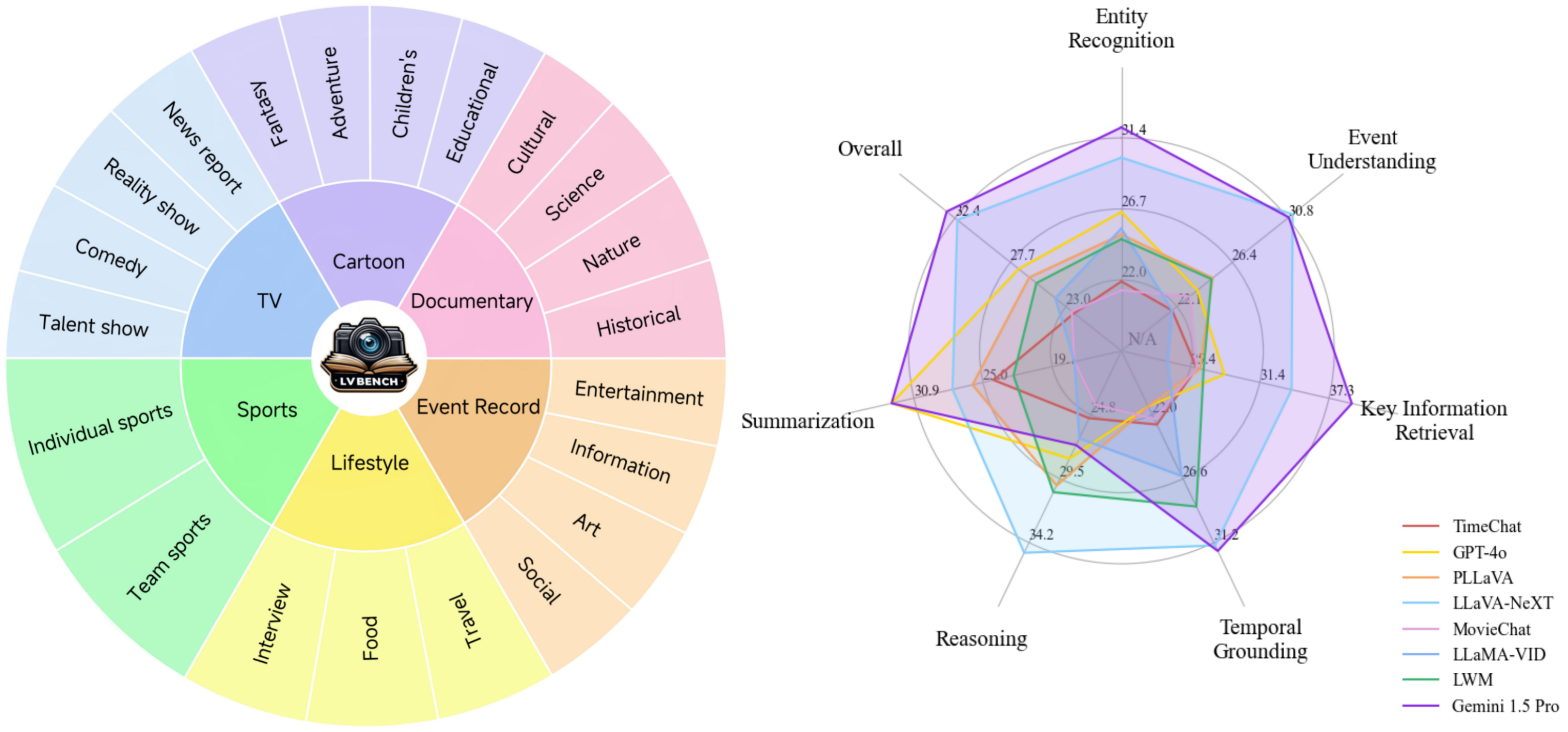
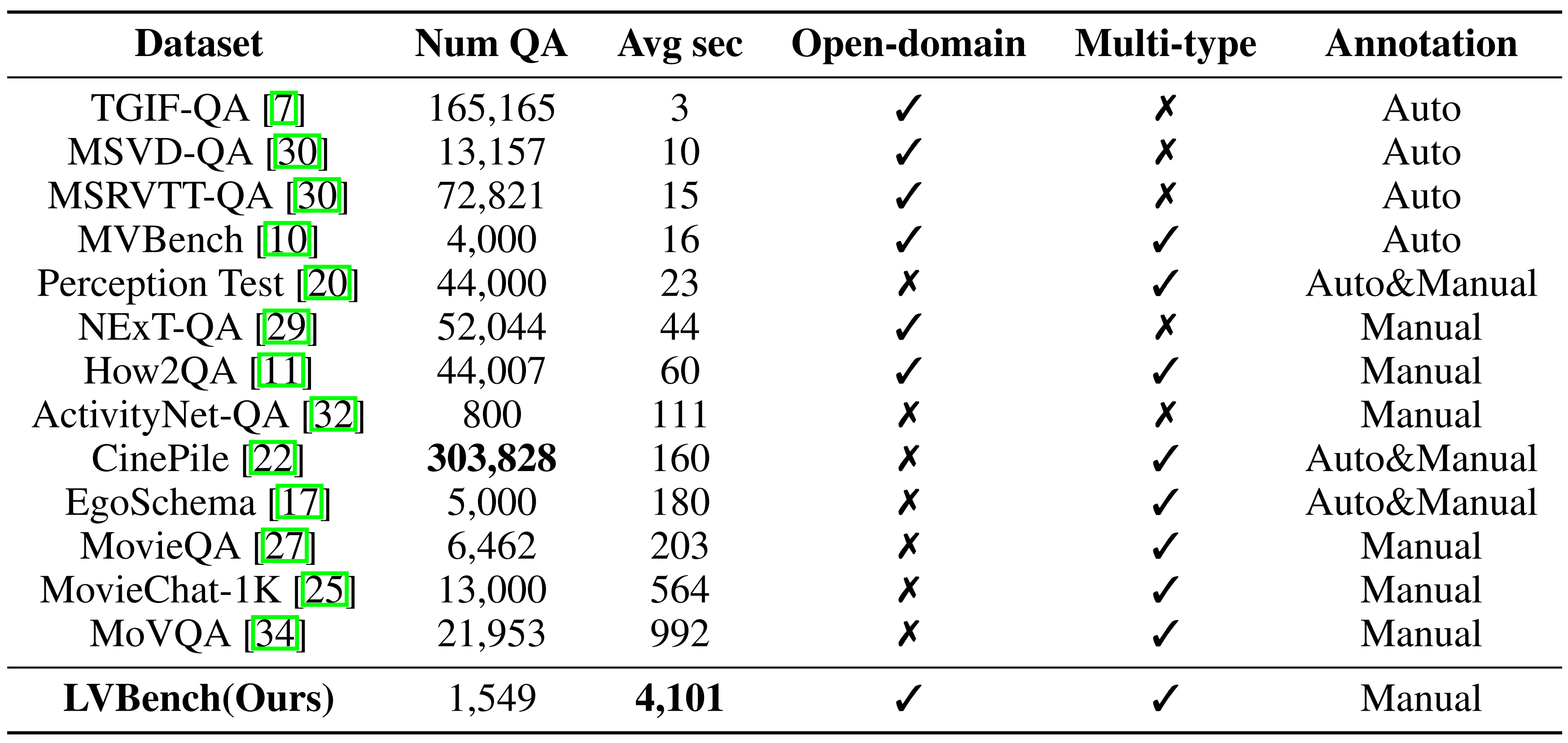
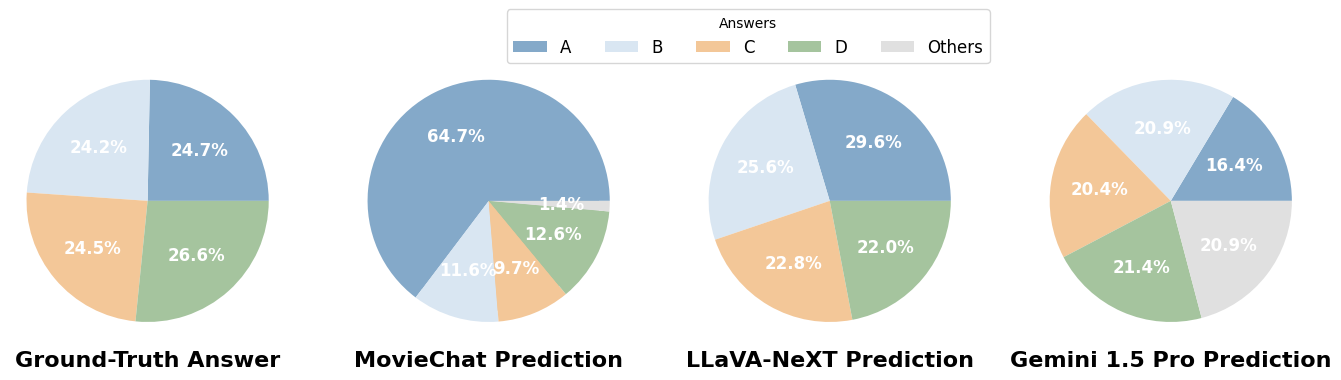
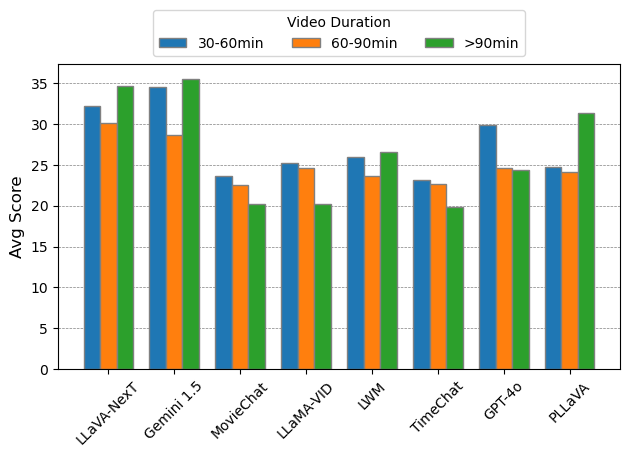
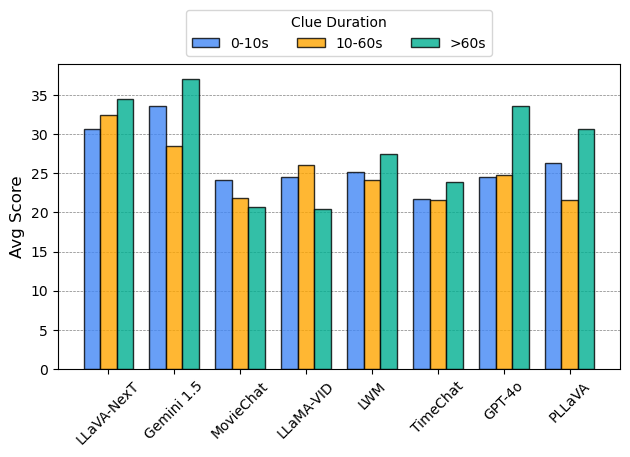
Accuracy scores on LVBench.
| # | Model | Frames | LLM Params |
Date | Overall (%) | ER (%) | EU (%) | KIR (%) | TG (%) | Rea (%) | Sum (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Deep Video Discovery
Microsoft |
- | - | 2025-5-29 | 74.2 | 73.4 | 73.3 | 80.4 | 72.3 | 70.6 | 74.1 | |
| Seed1.5-VL-Thinking
ByteDance |
- | 200B(A20B) | 2025-5-14 | 64.6 | 65.4 | 63.4 | 68 | 53.6 | 63.7 | 46.6 | |
| AdaReTaKe
Huawei |
≤1024 | 72B | 2025-3-4 | 53.3 | 53 | 50.7 | 62.2 | 45.5 | 54.7 | 37.9 | |
| GPT-4o-2024-11-20*
OpenAI |
60 | - | 2025-4-30 | 48.9 | 48.9 | 49.5 | 48.1 | 40.9 | 50.3 | 50 | |
| GLM-4V-Plus-0111
Zhipu AI |
≤300 | - | 2025-1-24 | 48.7 | 46.2 | 47.8 | 54.1 | 42.7 | 46.5 | 37.9 | |
| InternVL2.5-78B
Shanghai AI Lab |
16 | 72B | 2025-1-24 | 43.6 | 43.8 | 42 | 42.1 | 36.8 | 51 | 37.9 | |
| mPLUG-Owl3
Alibaba |
64 | 7B | 2024-11-23 | 43.5 | 46 | 41.6 | 42.4 | 41.1 | 47.5 | 40.4 | |
| Qwen2-VL-72B
Alibaba |
48 | 72B | 2024-09-20 | 41.3 | 38.0 | 41.1 | 38.3 | 41.4 | 46.5 | 46.6 | |
| TimeMarker
Meituan |
≤128 | 8B | 2024-10-29 | 41.3 | 42.8 | 39.1 | 34.9 | 38.7 | 38.2 | 48.8 | |
| InternVL2-40B
Shanghai AI Lab |
16 | 34B | 2024-08-30 | 39.6 | 37.4 | 39.7 | 43.4 | 31.4 | 42.5 | 41.4 | |
| GLM-4V-Plus
Zhipu AI |
30 | - | 2024-08-30 | 38.3 | 39.9 | 35.8 | 34.8 | 37.7 | 40 | 32.8 | |
| Gemini 1.5 Pro
|
3600 | - | 2024-06-11 | 33.1 | 32.1 | 30.9 | 39.3 | 31.8 | 27 | 32.8 | |
| LLaVA-NeXT-Video-DPO (34B)
Bytedance & NTU S-Lab |
32 | 34B | 2024-06-11 | 32.2 | 30.1 | 31.2 | 34.1 | 31.4 | 35 | 27.6 | |
| Oryx-34B
Tsinghua University & Tencent & NTU |
64 | 34B | 2024-09-30 | 30.4 | 27.4 | 29.2 | 32.1 | 29.1 | 34 | 39.7 | |
| GPT-4o(2024-05-13)*
OpenAI |
348 | - | 2024-08-30 | 30.8 | 33.0 | 27.4 | 34.5 | 25.0 | 27.5 | 24.1 | |
| CogVLM2-Video
Zhipu AI |
24 | 8B | 2024-08-30 | 28.1 | 28.3 | 27.1 | 31.0 | 25.5 | 25.5 | 38.9 | |
| GPT-4o
OpenAI |
10 | - | 2024-06-11 | 27 | 26.5 | 23.7 | 28.3 | 21.4 | 28 | 32.8 | |
| PLLaVA 34B
Bytedance & NTU |
16 | 34B | 2024-06-11 | 26.1 | 25.0 | 24.9 | 26.2 | 21.4 | 30.0 | 25.9 | |
| LWM
UC Berkeley |
>3600 | 7B | 2024-06-11 | 25.5 | 24.7 | 24.8 | 26.5 | 28.6 | 30.5 | 22.4 | |
| LLaMA-VID
CUHK & SmartMore |
>10800 | 13B | 2024-06-11 | 23.9 | 25.4 | 21.7 | 23.4 | 26.4 | 26.5 | 17.2 | |
| MovieChat
Zhejiang University |
>10000 | 7B | 2024-06-11 | 22.5 | 21.3 | 23.1 | 25.9 | 22.3 | 24.0 | 17.2 | |
| TimeChat
Peking University & Huawei |
>96 | 7B | 2024-06-11 | 22.3 | 21.9 | 21.7 | 25.9 | 22.7 | 25.0 | 24.1 |
Green date indicates the newly added/updated models.
* All the frames are resized to 512x512 resolution to fit within GPT-4o’s max context length.